Python 中文编码
前面章节中我们已经学会了如何用 Python 输出 "Hello, World!",英文没有问题,但是如果你输出中文字符"你好,世界"就有可能会碰到中文编码问题。
Python 文件中如果未指定编码,在执行过程会出现报错:
#!/usr/bin/python print "你好,世界";
以上程序执行输出结果为:
File "test.py", line 2 SyntaxError: Non-ASCII character '\xe4' in file test.py on line 2, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
Python中默认的编码格式是 ASCII 格式,在没修改编码格式时无法正确打印汉字,所以在读取中文时会报错。
解决方法为只要在文件开头加入 # -*- coding: UTF-8 -*- 或者 #coding=utf-8 就行了
注意:#coding=utf-8 的 = 号两边不要空格。
输出结果为:
你好,世界
所以如果大家在学习过程中,代码中包含中文,就需要在头部指定编码。
注意:Python3.X 源码文件默认使用utf-8编码,所以可以正常解析中文,无需指定 UTF-8 编码。
注意:如果你使用编辑器,同时需要设置 py 文件存储的格式为 UTF-8,否则会出现类似以下错误信息:
SyntaxError: (unicode error) ‘utf-8’ codec can’t decode byte 0xc4 in position 0: invalid continuation bytePycharm 设置步骤:
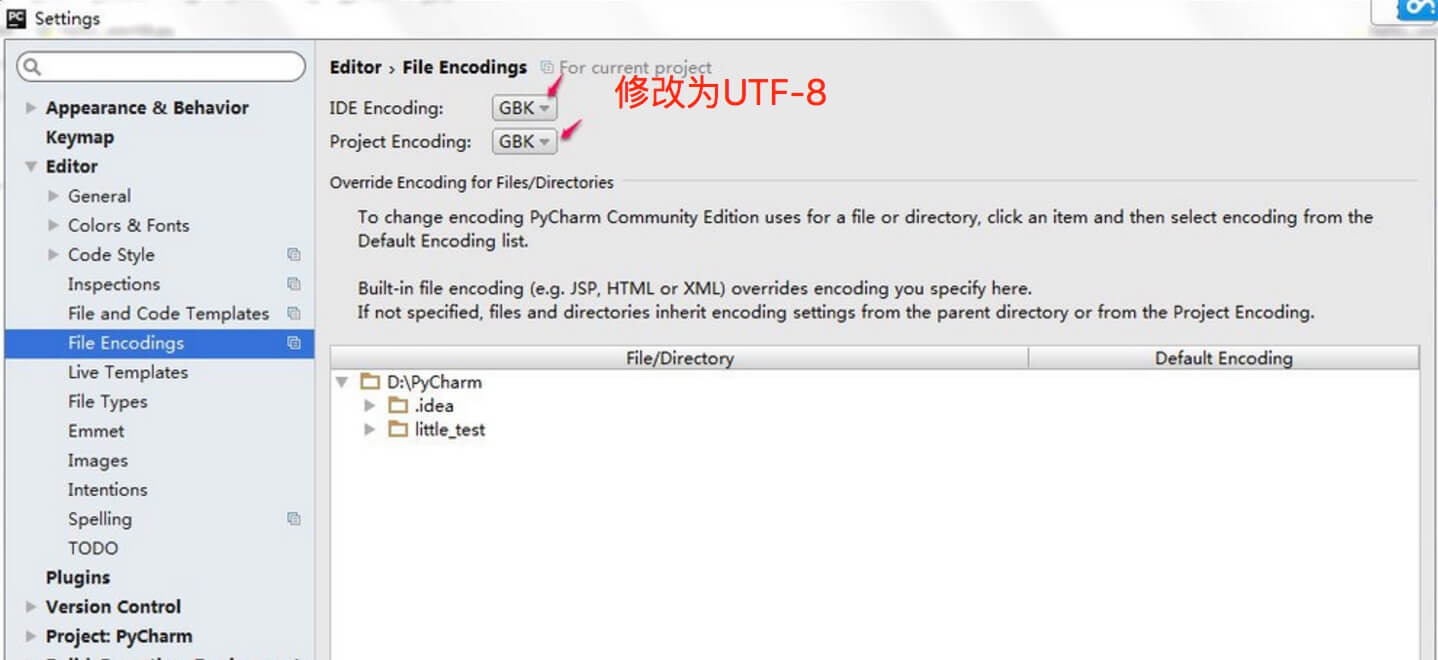
- 进入 file > Settings,在输入框搜索 encoding。
- 找到 Editor > File encodings,将 IDE Encoding 和 Project Encoding 设置为utf-8。





Airmin
lau***ceair@gmail.com
其实pycharm右下角就可以切换编码,不用这么麻烦:
但是,如果你文件已经指定了编码 # -*- coding: UTF-8 -*-,这里就不能修改了:
Airmin
lau***ceair@gmail.com
wxfjf
wxf***qq.com
python2.x 脚本加上 # -*- coding: UTF-8 -*- 或者 #coding=utf-8 后windows 命令提示符下输出中文字符串还会出现乱码。
解决方法需要先使用 decode("utf-8") 转换成 utf-8 编码,然后使用 encode("gbk") 转换成 gbk 编码,才能在 windows 命令提示符下正常输出中文。
例如:
>>> # -*- coding: UTF-8 -*- >>> s="我是中文 " >>> print s.decode("utf-8").encode("gbk")原因是 windows 命令提示符的显示编码为 gbk 编码。
在命令提示符下使用 chcp 查询编码。
"活动代码页:936" 代表命令提示符的编码为 "gbk"
"活动代码页:65001" 代表命令提示符的编码为 "utf-8"
wxfjf
wxf***qq.com
糖宝爱睡觉
tjy***80106@163.com
在 Eclipse 中调试 python 例子时候,提示:
基本知识:在 python 中默认的编码格式是 utf-8。所以怎么会报不能按 utf-8 来解码嘞?一头雾水啊。
问题的解决:
1、Eclipse 中 Window->Preferences:
最后在 Eclipse 安装目录中的 eclipse.ini 文件最后加上 -Dfile.encoding=UTF-8 就行了,最终写入文件的中文就不会出现乱码的问题了。
2、使用 notepad++ 打开 test.py 发现文件存储的格式是 ANSI。
只要将保存文件的格式换成 UTF-8 就好了。
糖宝爱睡觉
tjy***80106@163.com